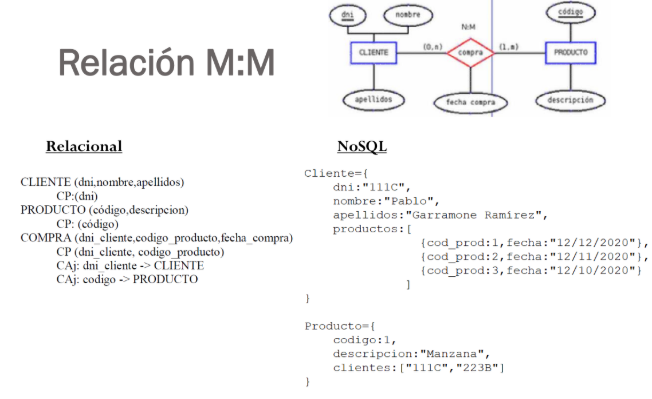
Diferències entre NoSQL i Relacional. Nomenclatura.
Diferències NoSQL i relacional
Comparativa Relacional vs NoSQL
Els entorns NoSQL més usuals són:
Exemples de quan podem triar cada model:
JSON: JavaScript Object Notation
1.Introducció a NoSQL
NoSQL no es refereix a que no utilitze SQL, sinó que significa NO NOMÉS SQL (NoSQL = Not Only SQL).
No és tant una qüestió de relacional o no relacional, sinó que estem parlant d’una estructura alternativa per a tractar les BD (bases de dades) davant un problema de rendiment.
És mirar la vessant relacional d’una BD des d’un altre punt de vista, amb una estructura més flexible y amb menys limitacions que el relacional.
Els dos models apareixen en els 70-80. SQL començà a ser el més popular però en els últims anys ha començat a ser-ho el NoSQL. Però NoSQL no és un substitut del relacional, sinó més bé una alternativa en determinades circumstàncies.
Per què sorgeix NoSQL?
Apareix amb el Web 2.0. Fins eixe moment només les grans companyies pujaven contingut a Internet però amb l’aparició de plataformes com Google, Amazon, Facebook, etc., qualsevol usuari podia pujar contingut, cosa que va provocar un increment de les dades.
És en eixe moment quan comencen a aparèixer els primers problemes de rendiment en els sistemes de BD relacionals. En un primer moment s’opta per ampliar el HW, però era molt costós i no solucionava bé el problema. Finalment s’opta per una solució SW: el NoSQL.
NoSQL permet superar els problemes d’escalabilitat i rendiment que es produeixen en els sistemes de BD relacionals quan es troben grans volums de dades, gran quantitat d’usuaris en concurrència i milions de consultes diàries.
Estos sistemes NoSQL estan optimitzats per a tasques de recuperació i agregació d’informació (insert i select), però no és una prioritat la seua actualització (update).
Principis NoSQL
NoSQL es basa en 4 principis:
- El control transaccional ACID (*) no és important.
- Els JOINS tampoc són importants. En especial els complexes i distribuïts.
- Alguns elements relacionals són necessaris i aconsellables: claus (keys).
- Gran capacitat d’escalabilitat i de replicació en múltiples servidors.

Tipus de NoSQL
Les BD NoSQL són sistemes d'emmagatzemament d’informació que no compleixen l’esquema Entitat-Relació, ni l’estructura de taula on es guarden les dades. Estos sistemes emmagatzemen la informació mitjançant:
- Clau - Valor
- Documents
- Mapeig de columnes
- Grafs
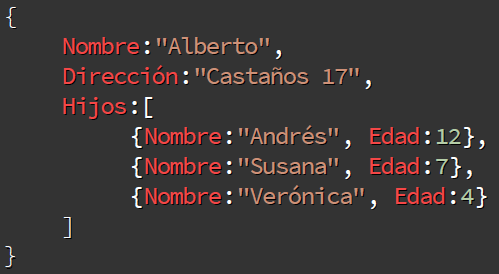
En les BD documentals, en el nostre cas MongoDB, els documents seran estructures JSON.
Les orientades a grafs estan formades per un conjunt d’objectes anomenats nodes, connectats mitjançant una sèrie d’arestes (per exemple, el gestor de BD NoSQL Neo4j)
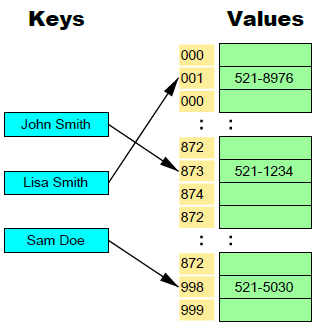
En les BD clau-valor, la BD emmagatzema en parells clau/valor. (Redis)
Clau- Valor
Són les habituals en els SGBD NoSQL perquè són les més senzilles pel que fa a la funcionalitat.
En este sistema, cada element és identificat per una clau única, permetent així una recuperació ràpida. Són molt eficients en lectura i escriptura.
Per exemple Cassandra i Redis.
Documentals
La informació s’emmagatzema com un document. Utilitza una estructura simple com JSON o XML. En ell s’utilitza una clau única per cada registre.
A més de realitzar cerques per clau-valor, es poden fer cerques més avançades pel contingut del document.
Per exemple MongoDB i CouchDB.
Grafs.
La informació es representa com nodes d’un graf, i les seus relacions com les arestes entre els nodes, de forma que per a recórrer la informació es pot aplicar la teoria de grafs.
Permet mantindre el rendiment, sense importar que cresca la BD.
Usem BD NoSQL? o Relacional?
No és una decisió súper important, ja que podem dissenyar qualsevol cosa amb els dos models, encara que en determinades situacions serà millor un o altre.
El que realment importa, es trie el model que es trie, és fer un bon disseny. Poc importa si encertem el model si després ho dissenyem malament.
Diferències entre NoSQL i Relacional. Nomenclatura
| SQL | NoSQL |
|---|---|
| BD | BD |
| Taula | Col·lecció |
| Fila | Document |
| Columna | Camp |
| Estructura tabular | Objectes JSON |
Imaginem que tenim una plataforma online de cursos d’idiomes, i triem usar un model relacional, però hem fet mal el disseny:
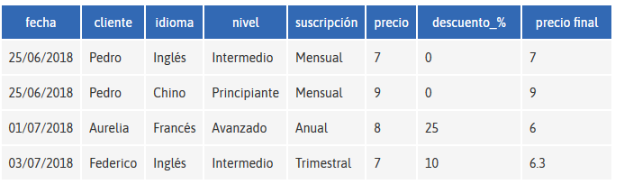
Ens adonem que no està normalitzada ja que el nivell i el preu depenen de l’idioma, el descompte depén del tipus de subscripció, etc.
Per tant, normalitzem i obtenim estes taules:
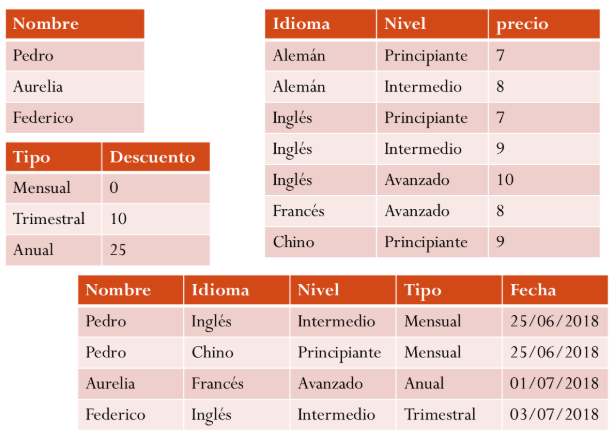
En NoSQL tenim l’alternativa desnormalitzada:

Dos implementacions vàlides.
Diferències NoSQL i relacional
- No utilitzen el llenguatge SQL en les consultes.
- No utilitzen estructures d'emmagatzemament fixes per a guardar la informació, sinó que fan ús d’altres models, com sistemes clau-valor, grafs o objectes.
- No solen permetre operacions de JOIN. Com solen tindre un volum de dades extremadament gran, resulta incòmode utilitzar JOIN ja que sobrecarrega el sistema. La solució a este problema pot ser la desnormalització o fer el JOIN per software en la capa d’aplicació.
- Arquitectura distribuïda. Les BD relacionals solen estar centralitzades en una màquina o amb estructura client-servidor. Però els sistemes NoSQL poden contindre la informació compartida entre diverses màquines mitjançant taules hash distribuïdes.
Comparativa Relacional vs NoSQL
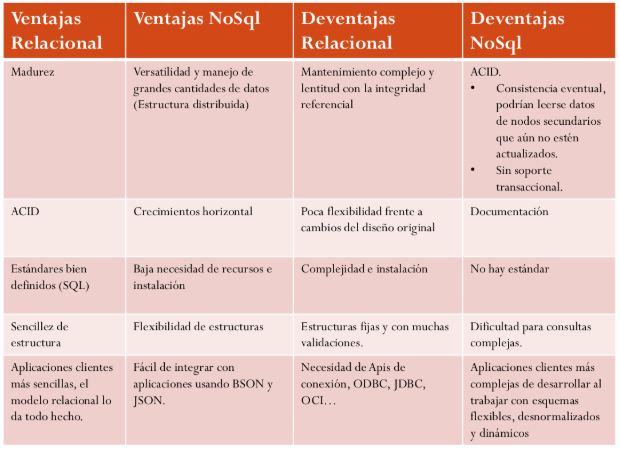
Què ofereix NoSQL
- Són idònies si les dades no segueixen una estructura fixa.
- No garantixen els principis ACID
- EL model és flexible. Milloren la flexibilitat i escalabilitat respecte de les BD SQL. Les dades que utilitzen les nostres aplicacions web, mòbils o xarxes socials canvien constantment.
- Versatilitat. La modificació és més senzilla que en els models relacionals. A l’hora de modificar o introduir nous tipus de dades no tenim la necessitat de modificar per complet l’estructura de la BD.
- Alt rendiment. La velocitat és un dels factors més importants.
Quan triar NoSQL
- Quan l'escalabilitat en un model relacional no és viable o molt costós, tant a nivell tècnic com de costos.
- Quan el sistema té pics d'ús molt elevats per part dels usuaris.
- Quan la quantitat de dades creix ràpidament en situacions puntuals (més d’1 Tb).
- Quan la informació no és homogènia. És a dir, quan en cada inserció podem tindre diferents camps.
- Quan ens interessa més la velocitat de les lectures que la seguretat de l'escriptura.
- Quan no tenim la necessitat d'una gran normalització de les dades i podem tindre-ho desnormalitzat.
Els entorns NoSQL més usuals són:
- Xarxes socials: quasi obligatori.
- Desenvolupament web: a causa de la poca uniformitat de la informació que es troba en Internet. Encara que també pot usar-se SQL.
- Desenvolupament mòbil: a causa de la tendència (en creixement) de Bring Your Own Device.
- BigData: a causa de l'administració de grandíssimes quantitats d'informació i la seua evident heterogeneïtat.
- Cloud (XaaS): “Everything as a service”; NoSQL pot adaptar-se quasi a qualsevol necessitat del client i les seues particularitats.
Exemples de quan podem triar cada model:
- Quan el nostre pressupost no ens pot permetre grans màquines i ha de destinar-se a màquines de menor rendiment, NoSQL.
- Quan les estructures de dades que manegem són variables, o no la tenim clara inicialment NoSQL.
- Anàlisi de grans quantitats de dades en manera lectura, NoSQL.
- Captura i processament d'esdeveniments, NoSQL.
- Botigues en línia amb motors d'intel·ligència complexos, NoSQL.
- Quan les dades han de ser consistents sense donar possibilitat a l'error, BD relacional, SQL
- En quasi tots els altres casos, SQL.
En NoSQL, les dades es recuperen, en general, de forma més ràpida que el Model Relacional, no obstant això les consultes que es poden realitzar són més limitades. La complexitat es trasllada a l'aplicació.
Si la teua aplicació requereix suport transaccional, has d’usar un model Relacional, no reinventes la roda.
NoSQL no és adequat per a aplicacions que generen informes amb consultes complexes (necessitat de JOINs), encara que existeixen operacions en NoSQL que permet paral·lelitzar operacions complexes com a agregacions, filtres, etc.
La tendència actual és combinar sistemes SQL i NoSQL
2. MongoDB
MongoDB és un gestor de BD estructurat sota NoSQL que compta amb un format d'emmagatzematge de documents en un format similar al JSON (JavaScript Object Notation). Està escrit en llenguatge C++, és multiplataforma en codi obert i completament gratuït. Es va crear en 2007 per l’empresa 10Gen. Mongo ve de la paraula anglesa «humongous», que significa «enorme, extraordinàriament deixe anar». El seu disseny va ser desenvolupat per a ser implementat en una aplicació d'internet que l'empresa desenvolupava i no va ser fins a l'any 2009 que decideixen alliberar-lo en format OpenSource.
MongoDB compta amb un emmagatzematge flexible basat en JSON. A més té suport per a la creació d'índexs des de qualsevol atribut. També és important destacar que té un alt rendiment per a consultes i actualitzacions. És increïblement flexible i potent la seua capacitat de creixement, replicació i escalabilitat.
MongoDB és ideal per a crear aplicacions en línia que requerisquen el registre de diverses dades. O per a la creació i disseny de programari que siguen flexibles quant a tractament d'alts volums d'informació. Les Bases construïdes sota aquest disseny poden rebre centenars de milers de lectures per segon sense que el seu rendiment es veja afectat o disminuït.
Que ofereix MongoDB
- Orientada a documents (JSON).
- No segueix cap esquema (schemaless).
- Disposa d'una consola (shell) construïda sobre JavaScript el que permet executar moltes de les seues funcions.
- Àmpliament utilitzada en aplicacions per a Internet i de BigData.
- Escriptura ràpida: Les BD documentals estableixen un ordre de priorització de la disponibilitat d'escriptura per damunt de l'estricta consistència de les dades.
- Llenguatge de Consultes Avançat. Els seus mètodes d'agregació per a bigdata és el millor que hi ha.
- Alta disponibilitat: Replicació dels set i balanceig de càrrega és molt senzill i es fa en 4 passos.
- Escalabilitat horitzontal: Alçar un clúster és senzill.
- Consola JS: Es treballa en aquest llenguatge per als comandos de Mongo.
JSON: JavaScript Object Notation
És un format de text senzill per a l'intercanvi de dades. Presenta un alternaiva a XML perque és més senzill de llegir i escriure. A més a més, esta suportat per un gran nombre de llenguatges.
Un Objecte JSON està format per un o varios parells string:valor.
La sintaxi en JSON és molt senzilla, partim de la dupla identificador:valor i segons l'estructura formarem variables, arrays, etc.
- Creació d'arrays amb claudàtors ([]).
- Creació d'objectes amb claus ({}).
- Separació del nom i/o assignació de valor amb dos punts (:).
- Separació de valors amb coma (,).
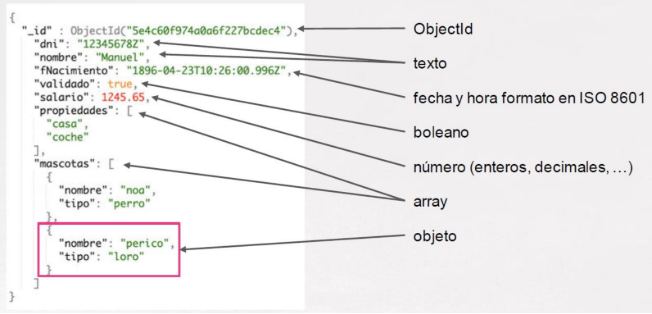
Exemple detallat de document JSON
3. Modelat Mongo
Modelat de dades
El model NoSQL és àgil i flexible i val tot. Com ja hem vist, accepta qualsevol cosa i qualsevol estructura. Podem tindre un E-R de partida i el seu disseny conceptual (traducció), és el més recomanable, encara que si tenim un model gran amb moltes relacions, és una pista que potser hauríem d'usar el model relacional i no el NoSQL. O també no tindre cap model i anar afegint estructures sobre la marxa, generalment quan ens decantem per NoSQL és perquè no hi ha moltes entitats, ni les relacions són massa importants. Al final sempre acabarem dissenyant un model quan l'anem tenint clar, però tenim la flexibilitat de no requerir un model predefinit, almenys al principi.
Opcions de modelatge
En Mongo disposem de dues estructures diferents per a dissenyar relacions en les nostres col·leccions:
Embegudes: El que anomenaríem "entitats" en el disseny conceptual, en aquest cas tindríem una entitat dins d'una altra formant 1 sola col·lecció. El que podria dir-se subdocuments.
Referenciades: Quan ens interessa tindre les "entitats" separades i llavors referenciem d'una forma semblant a com ho fem en el model relacional, amb unes foreign key simulades. En aquest cas haurem de tindre alguna cosa semblant a una clau primària (per defecte mongo té el camp _id).
NoSQL està pensat per a embeure, però tampoc podem crear un document infinit ni repetitiu. A vegades ens convindrà referenciar, simulant les famoses FK (encara que moltíssim menys restrictives) i, com veurem, les col·leccions poden tindre PK i UK.
Triar entre embeure o referenciar depén totalment de l'aplicació:
- Com treballarem amb les dades
- Com preveiem que vagen a evolucionar
- Com creixen
- Quan s'accedeix a ells i a quins exactament
- Com volem emmagatzemar les dades
- ….
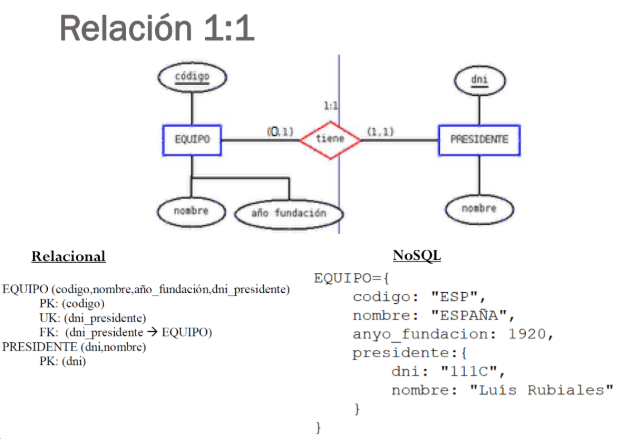
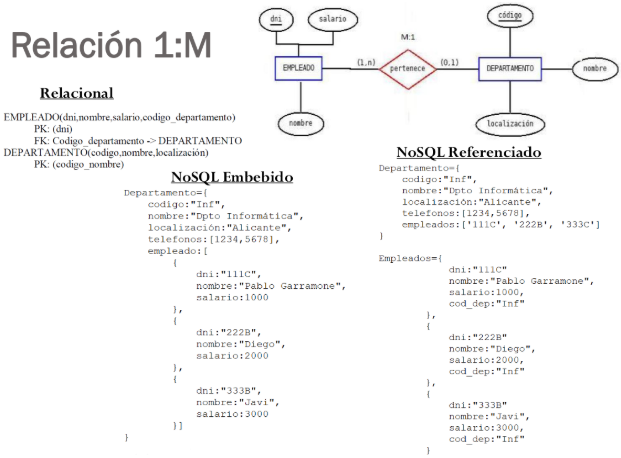
Embeure o referenciar
- En les relacions 1:1 interessa embeure, ja que d'aquesta manera tenim tota la informació en la mateixa col·lecció, cosa que facilita la seua consulta.
- En una relació 1:M, dependrà de la relació:
- Si un element no es relaciona amb “moltíssims”, ens pot interessar embeure ja que sempre facilitarà la consulta.
- Però si es pot relacionar amb “moltíssims” (1 milió per exemple) serà millor referenciar, ja que si embeguem tindrem dos problemes:
- De grandària: Cal anar amb compte perquè Mongo té una limitació de 16Mb per cada document i no podrem inserir-lo.
- De recerca: si hem de fer una consulta, i just busquem l'últim no serà gens òptim.
- Si requerim moltes consultes sobre els subelements exclusivament, pot interessar-nos tindre-ho en una col·lecció solta. Per això serà millor referenciar.
- En les M:M, normalment serà convenient referenciar, perquè si 1 document es relaciona amb molts de l'altra col·lecció, este es repetirà en cadascun dels documents relacionats, cosa que generarà una tremenda redundància.
- Per norma general hem d'embeure, de manera que tinguem el màxim d'informació possible dins del mateix document, evitant "JOINS", ja que en Mongo l'atomicitat és per document, de manera que els JOINS no són trivials.
- Si el subdocument embegut es repeteix moltíssimes vegades o realitzem recerques exclusives sobre ell, és millor referenciar.
- Si la llista de subdocuments creixerà indiscriminadament, és millor referenciar (tindre en compte la limitació dels 16Mb) ja que si hi ha massa informació la consulta és ineficient.
| Embeure | Referenciar |
|---|---|
| Xicotets subdocuments | Grans subdocuments |
| Lectura ràpida. Tenim tota la informació en un sol document | Lectura òptima, si embeguts hi haguera molts subdocuments. Inconvenient del JOIN |
| Documents que creixen en xicotetes quantitats o no canvien regularment | Documents que creixen en gran quantitat. |
| Escriptures òptimes si no s’actualitza informació relacionada. | Escriptures ràpides. En actualitzar informació relacionada, es fa directament sense haver de relacionar la col·lecció externa. |
3. Disseny Físic. DDL Mongo
Per a instal·lar MongoDB:
https://www.mongodb.com/docs/manual/tutorial/
Primers comandaments que podem provar:
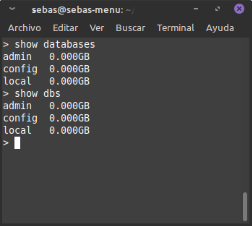
- show dbs / show databases : ens mostra totes les BD que tenim en mongo
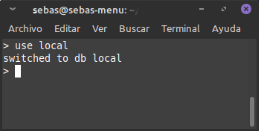
- use
: per accedir a una BD.
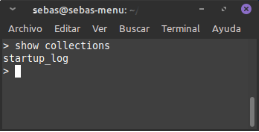
- show collections : per vore les col·leccions que tenim a una BD.
- db.stats() : ens dona els detalls i estadístiques generals de la BD.
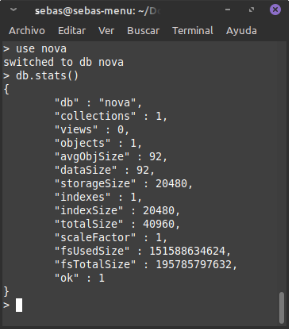
- db.help() : proporciona ajuda dels comandaments de mongo.
- db : indica la BD actual.
## Crear una BD
No hi ha cap mètode específic per crear una BD, en el moment que creem una col·lecció automàticament es crea la BD.
- Primer accedim a la BD nova (encara que no existisca)
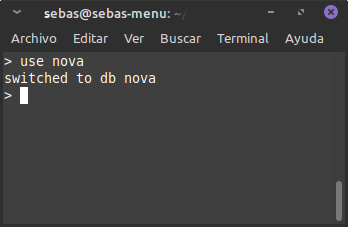
- Una vegada dins hem de crear una col·lecció. Atenció! Amb “use” encara no s’ha creat res. Si no creem la col·lecció, la BD no s’haurà creat.
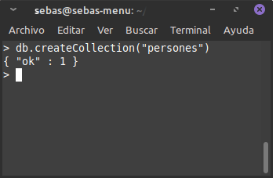
Crear una col·lecció
Tenim dues opcions per crear les col·leccions:
- db.createCollection(
, [opcions]) : ens permet crear una col·lecció utilitzant les distintes opcions de configuració. Esta opció és interessant quan el projecte està clar, definit i estan clares les limitacions que anem a posar-li.
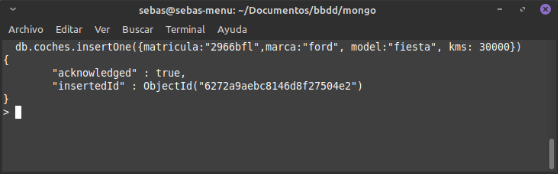
- db.
.insert( ) : li diguem a Mongo que faça una inserció en la col·lecció i, si Mongo detecta que no existeix, la crea. Esta es l’opció més habitual quan comencem i encara no tenim clares les limitacions que anem a donar-li a la col·lecció.
## Eliminar col·leccions i BD
- db.
4. DML Bàsic Mongo
Consideracions inicials
- Hem de tindre en compte que en Mongo tot són documents JSON. Per tant, sempre tindrem duples camp:valor. Els valors sempre van entre cometes.
- En els elements de Mongo es posarà un $ davant.
- Quan vullgam accedir a elements dels subdocuments haurem de posar-los entre cometes i fins i tot en funcions complexes amb $.
- Qualsevol element tindrà {} i tindrem alguns amb array []
- Totes les operacions comencen per db, que indica data base (base de dades) i serà l'última que haurem posat “use”.
Operacions bàsiques. CRUD (Create/Read/Update/Delete)
- INSERIR: insert / insertOne / insertMany
- ESBORRAR: remove / deleteOne / deleteMany
- MODIFICAR: update/ updateOne / updateMany / replaceOne / save
- CONSULTAR: find (i les seues variants).
Operacions d’inserció
Tenim 3 mètodes d'inserir:
- insert(JSON): Pots inserir un o diversos documents alhora. Està obsolet en alguns drivers.
- insertOne(JSON): És la nova versió per a quan només volem inserir 1 document.
- insertMany([JSON]): És la nova versió per a quan volem inserir més d'1 document.
Sintaxis: db.
Tenim dos formes d’inserir el JSON:
Definit en una variable Javascript
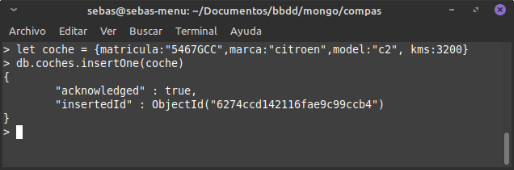
Directament:
Inserir diversos documents:
db.
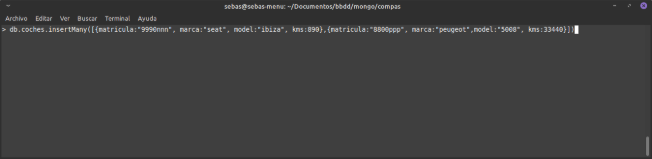
Cal dir que Mongo és atòmic per document. És a dir: si falla un dels documents de l’insert, no s’inseriran els documents que figuren després, però sí els d’abans.
Operacions d’esborrat
Per a eliminar tenim opcions, com en l’insert:
- deleteOne(filtre), sols esborra el primer document que trobe que complisca el filtre.
- deleteMany(filtre), esborra tots els documents que complisquen el filtre.

Operacions de modificació
-
db.
.updateOne(filtre, acció, opcions) -
db.
.updateMany(filtre, acció, opcions) - db.
.replaceOne(filtre, canvi, opcions), canvia un document per un altre.
filtre: és com el where de MySQL
acció: les accions que anem a realitzar per a fer actualitzacions.
opcions: Opcions alternatives que podem configurar per a realitzar coses extres en l’operació.
Accions
- $set: Defineix la clau que s'actualitzarà (o crearà si no existira). El més habitual.
- $inc: Incrementa el valor d'un camp numèric.
- $rename: Canvia de nom el nom d'una clau.
- $unset: Defineix la clau del document que s'eliminarà.
- $currentDate: Actualitza un camp a la data actual.
- $, $[...], $[
]: Marques d'elements - $pull: Elimina els valors d'un array que complisquen el filtre.
- $pullAll: Elimina els valors especificats d'un array.
- $pop: Elimina el primer o últim valor d'un array.
- $push: Afig un element a un array.
- $position: S'usa amb push per a indicar la posició exacta on afegir elements.
- $slice: S'usa amb push per a limitar la grandària final de l'array.
- $sort: S'usa amb push per a reordenar els elements afegits.
- $addToSet: Afig elements a un array si no existeixen.
- $each: S'empra amb $addToSet i $push per a permetre l'agregació múltiple d'elements a un array.
Exemple d’update:
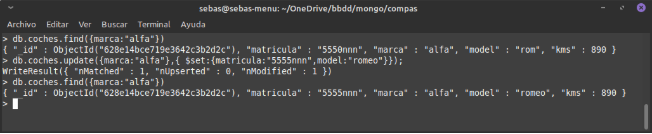
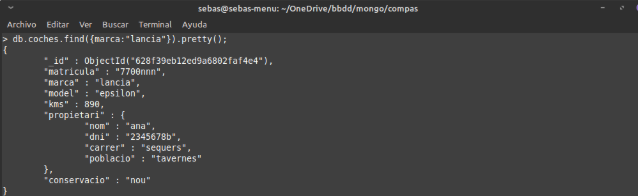
Cap remarcar que si fem un update d’un document que té un objecte embegut, cal posar totes les dades d’eixe objecte. Si no, es perden els camps de l’objecte.
Ací tenim un exemple de com es perd la informació del propietari que no hem modificat.
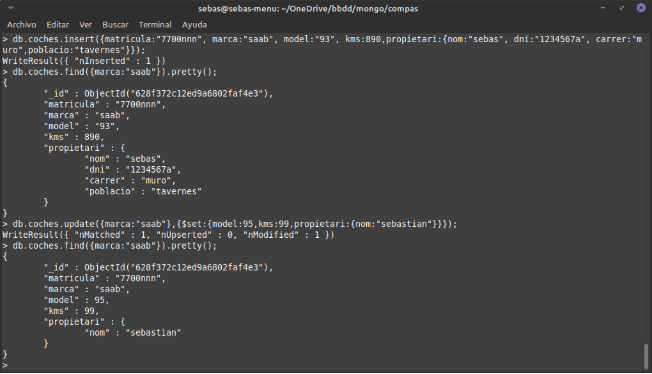
Exemple de update amb $inc per augmentar un valor numèric
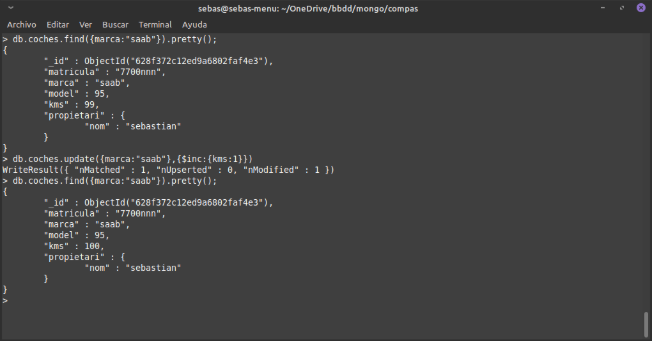
Exemple de update amb $rename, on vorem que es canvia el nom del camp, però es col·locarà al final del document.
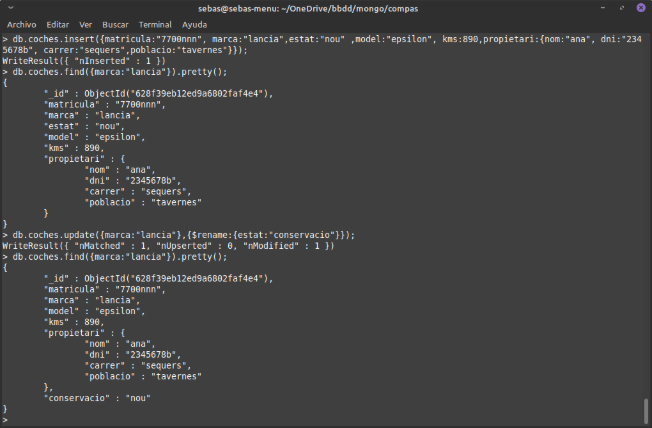
Per descomptat, podem canviar el nom del camp en tots els documents, encara que en este cas només un document tenia este camp.
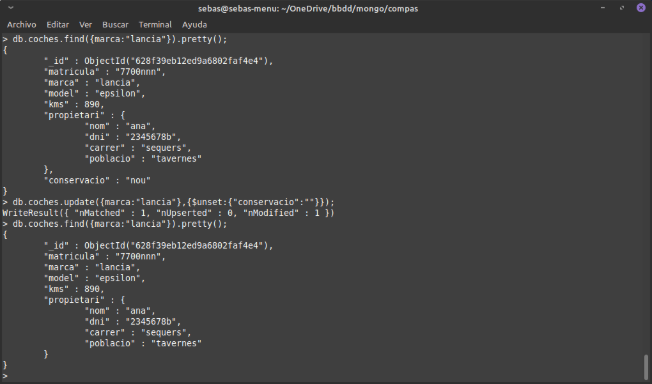
Exemple de update amb $unset, on eliminem un camp d’un document
Opcions
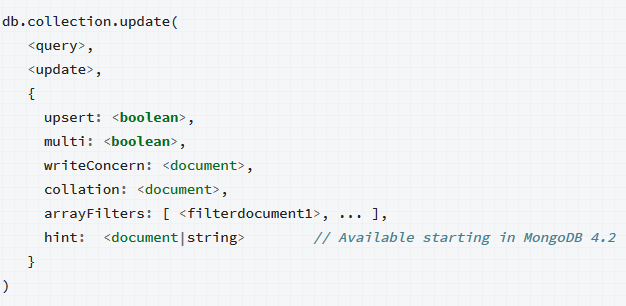
- Podem no posar cap opció.
- multi: Booleà, per defecte false. L'operació update només modifica el primer document que complisca el "where". Si posem este booleà a true, s'actualitzaren tots els documents que ho complisquen (farà com un updateMany).
- upsert: Booleà, per defecte false. Si un update no compleix el "where", l'operació no fa res, si posem este booleà a true, l'inserirà com un nou document.
- hint: Per a forçar que utilitze un índex determinat. Si l'índex que indiquem no existeix, donarà error.
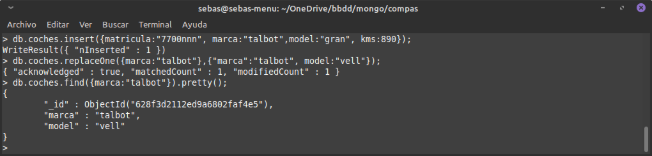
MODIFICAR. REPLACEONE
A diferència d'update, que només es modifiquen o afigen els elements que posem en l'apartat d'acció, amb replaceOne substituïm el document sencer pel que posem.
Amb esta operació només podem anar d’un en un, clar.
Operacions de consulta
Per a realitzar consultes s'utilitza l'operador FIND. És Important recordar que FIND busca DOCUMENTS, no subdocuments concrets.
Sintaxi:
db.
No hi ha cap filtre obligatori, si no posem res obtindrem tots els documents de la col·lecció.
- Les condicions en Mongo van en moltes operacions (find, aggregate, update...)
- $type: Per a consultar pel tipus de dades.
- $exists: Per a consultar si el camp existeix.
- $regex: Per a indicar una expressió regular a complir.
- $and, $nor, $or i $not: → Operadors booleans
- $in, $nin: → contingut en, no contingut en
- $eq: → true si els valors són equivalents
- $gt, $gte, $lt, $lte, $ne: → Major que, major que o igual...
- $where: Satisfer una expressió en javascript
- $all: Arrays que complisquen que tinguen tots els elements.
- $elementMatch: Especificacions a complir en Arrays
- $size: Indicar la grandària de l'array.
Exemple de find:
FIND $type
Com en NoSQL podem tindre un camp que unes vegades tinga un tipus de dada i altres vegades un altre, pot interessar-nos traure aquells documents on un determinat camp tinga un tipus concret.
Exemple: En una BD de pel·lícules i comentaris traure totes aquelles en les quals el títol està en un string
db.movies.find({title:{$type:"string"}}).pretty()
FIND $exists
S’utilitza per a traure aquells documents on existeix o no existeix el camp.
Per exemple, traure les pel·lícules on no apareixen actors:
db.movies.find{cast:{$exists:false}}.pretty()
FIND $regex
Per a utilitzar expressions regulars.
Per exemple, pel·lícules en les quals el seu títol comença per “The”.
db.movies.find({title:{$regex:/^The.*/}}).pretty()
FIND $and
Serveix per a afegir restriccions, i han de complir-se totes.
Per exemple pel·licules que comencen per “The” i siguen espanyoles:
Nota: “countries” és un array de països.
db.movies.find({$and:[{title:{$regex:/^The.*/}},countries:"Spain"]}).pretty()
Però no cal usar l’and ja que es fa de forma implícita. Açò trau el mateix resultat:
db.movies.find({title:{$regex:/^The.*/},countries:"Spain"}).pretty()
Però alerta! En cas de buscar distints valors en el mateix camp, sí que cal posar l’and.
Per exemple pel·lícules que siguen de Espanya i USA. És a dir: que continguen Espanya i USA dins del seu array de països:
db.movies.find({$and:[countries:"Spain",countries:"USA"]}).pretty()
FIND $or
En aquest cas fa un or lògic i sí que és necessari posar-lo.
Per exemple les pel·lícules que comencen per “El” o siguen espanyoles.
db.movies.find({$or:[{title:{$regex:/^El.*/}},{countries:"Spain"}]}).pretty()
FIND $not, $nor
$not, com ja sabem, és el contrari de la condició que acompanya.
Per exemple pel·lícules que no siguen espanyoles.
db.movies.find({countries:{$not:{$eq:”Spain”}}}).pretty()
$nor és negar les dos opcions. És a dir: ni açò ni allò.
Per exemple, pel·lícules que no són ni espanyoles ni de USA:
db.movies.find({$nor:[countries:"Spain",countries:"USA"]}).pretty()
FIND $eq
S’utilitza com a operador d’igualtat. Sol usar-se en companyia del not. Per exemple, pel·lícules que no siguen espanyoles:
db.movies.find({countries:{$not:{$eq:”Spain”}}}).pretty()
Projectar
Com fem en SQL, podem projectar i traure només alguns elements, o traure dades combinades. La sintaxi és la següent: {
Es posen parelles de:
db.movies.find({},{_id:0,title:1, countries:1}).pretty();
FIND Opcions extra
S’usa per a ordenar de forma ascendent (1) o descendent(-1).
Sort({element1:1 o -1, element2:1 o -1,.......})
Per exemple, per a ordenar les pel·lícules espanyoles per número de premis de forma descendent:
db.movies.find({countries:"Spain"}).sort({awards.win.numberInt:-1}).pretty()