| Tema | Título | Versión |
|---|---|---|
| 05 | Funciones y procedimientos | v 1.0 |
TEMA 5: Funciones y procedimientos
Tema 5: Funciones y Procedimientos almacenados
Introducción
Un procedimiento almacenado (PA) es un conjunto de instrucciones SQL que se almacenan en el servidor de la base de datos y se pueden ejecutar como una unidad. Los procedimientos almacenados permiten encapsular lógica de negocio compleja, mejorar el rendimiento y facilitar la reutilización del código.
En mySQL funcionan desde la versión 5.0.
¿Desde dónde se pueden invocar los procedimientos almacenados (PA)?
- De forma directa (por ejemplo: entorno textual de MySQL, Workbench, vsCode, etc.)
- Desde una aplicación que accede a la base de datos (por ejemplo: desde un programa Java, Javascript, PHP, etc.)
- Desde otro procedimiento almacenado
Información adicional
- En la tabla mysql.proc hay información de los procedimientos creados: nombre, propietario, base de datos donde está, etc.
- Si queremos usar transacciones dentro de un PA, en lugar de iniciarla con BEGIN debemos hacerlo con START TRANSACTION. Ahora bien: solo pueden usarse transacciones en procedimientos, no en funciones.
Ventajas e inconvenientes
En la figura que se muestra, aparecen dos arquitecturas de desarrollo de aplicaciones posibles, una hace uso de los PA, y la otra no:
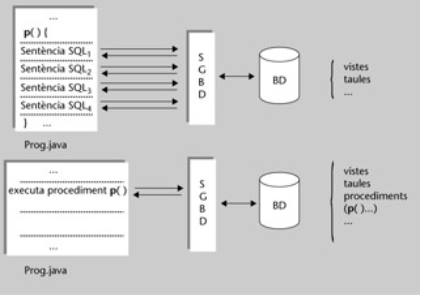
- Procedimiento no almacenado, hecho en Java, guardado en el programa (en el cliente). La parte superior de la imagen
- Procedimiento almacenado, hecho en MySQL, guardado en la BD (en el servidor). La parte inferior de la imagen
Ventajas
- Mejora el rendimiento ya que no es necesario enviar tanta información entre cliente y servidor. Se nota más esa mejora si cliente y servidor no están en la misma máquina.
- El PA puede ser utilizado por diferentes aplicaciones, independientemente del lenguaje y la plataforma.
- Facilita el trabajo al programador, ya que él sabe que existe un PA que le proporciona un determinado servicio, no necesita saber las sentencias SQL que incorpora el procedimiento, ni los elementos del esquema de la BD.
- Seguridad. Podemos quitar permisos a los usuarios sobre la BD y solo dar permisos sobre los procedimientos. Así controlamos de qué forma queremos que sean accedidos los datos.
Inconvenientes
-
Existe una dependencia con el SGBD utilizado. Es decir, cada sistema gestor de BD tiene su propio sublenguaje de PA:
SGBD Sublenguaje SQL para PA MySQL SQL 2003 PostgreSQL PLPGSQL Oracle PL/SQL + Java SQL Server T-SQL Por tanto si hacemos un PA con un sublenguaje de un SGBD y más adelante cambiamos de sistema gestor, tendremos que volver a hacer los procedimientos.
-
No hi ha eines de depuració de procediments emmagatzemats.
- No està permès l’ús de la ordre “USE nom_base_dades” dins d’un procediment per a canviar de BD. Ara bé: sí que es pot accedir a objectes d’altres BD amb el nom qualificat: nom_bd.nom_objecte.
Tipos: procedimientos y funciones
Hay dos tipos de rutinas que podemos crear en MySQL:
- procedimientos (
procedures) - funciones. (
functions)
Un procedimiento es un conjunto de tareas o acciones que no devuelven nada al usuario, en cambio, las funciones devuelven un valor. Al igual que en cualquier lenguaje de programación, la llamada también será diferente ya que las funciones deben recoger ese valor.
Procedimientos
Veamos las partes más comunes con un ejemplo. Supongamos que tenemos una base de datos con una tabla de artículos y queremos un procedimiento para que incremente el precio de un artículo.
Delimitador de sentencias
En MySQL, por defecto, el delimitador de sentencias es el punto y coma (;). Esto significa que cada vez que escribimos una sentencia SQL, debemos finalizarla con un punto y coma. Sin embargo, cuando estamos creando procedimientos o funciones, necesitamos usar un delimitador diferente para evitar confusiones. Por ejemplo, podemos usar // o $$ como delimitador temporal.
Veamos un ejemplo de cómo crear un procedimiento:
DELIMITER //
CREATE PROCEDURE incrementarPrecioArt(
IN codArt INT,
IN incremento DECIMAL(10,2)
)
BEGIN
DECLARE cantidad INT DEFAULT 0;
SET @encontrado = FALSE;
-- comprobamos si existe el artículo
SELECT COUNT(*) INTO cantidad
FROM articulos
WHERE codigo = codArt;
-- si el artículo existe, incrementamos su precio
IF cantidad = 1 THEN
BEGIN
SET @encontrado = TRUE;
UPDATE articulos
SET precio = precio + incremento
WHERE codigo = codArt;
END;
ELSE
-- si no existe, mostramos un mensaje
SET @encontrado = FALSE;
END IF;
END //
DELIMITER ;
Analicemos las partes principales:
- CREATE PROCEDURE: sentencia para crear el procedimiento, consta del nombre del procedimiento y los parámetros que recibe. En este caso, recibe el código del artículo y el incremento a aplicar al precio.
- IN: indica que el parámetro es de entrada, es decir, que se le debe pasar un valor al llamar al procedimiento. (Vermos más adelante otros tipos de parámetros).
- Parametros: se declaran entre paréntesis después del nombre del procedimiento, nombre y tipo de dato. En este caso,
codArtes un entero yincrementoes un decimal con dos decimales. - BEGIN ... END: delimitan el cuerpo del procedimiento, donde se encuentran las sentencias que se ejecutarán cuando se invoque el procedimiento.
- DECLARE: se usa para declarar variables locales dentro del procedimiento. En este caso, declaramos una variable
cantidadpara contar cuántos artículos hay con el código dado. SIEMPRE debemos declarar las variables justo después delBEGINdel procedimiento. - SET: se usa para asignar valores a las variables. En este caso, asignamos un valor inicial a
cantidady a la variable global@encontrado. - END //: indica el final del procedimiento. El
//es un delimitador que hemos definido para indicar el final del bloque de código del procedimiento, ya que dentro del procedimiento también usamos punto y coma para separar sentencias. - DELIMITER ;: volvemos a establecer el delimitador por defecto para las sentencias SQL.
Para llamar a un procedimiento necesitamos saber el nomnbre del procedimiento y los parámetros que requiere. En este caso, el procedimiento incrementarPrecioArt recibe dos parámetros: el código del artículo y el incremento a aplicar al precio.
Llamada al procedimiento
Para llamar a este procedimiento, usaríamos la sentencia CALL, la sintaxis general es:
CALL nombre_procedimiento(parametro1, parametro2, ...);
CALL incrementarPrecioArt(123, 10.50);
Variable global
La variable global @encontrado se usa para indicar si el artículo fue encontrado o no. Esta variable se puede consultar después de llamar al procedimiento para saber si se realizó la actualización.
SELECT @encontrado;
Para eliminar un procedimiento, la sintaxis es:
DROP PROCEDURE [IF EXISTS] nombreProcedimiento;
Para nuestro procedimiento sería:
DROP PROCEDURE IF EXISTS incrementarPrecioArt;
Modificación de procedimientos
Si queremos modificar un procedimiento ya existente, debemos eliminarlo primero con DROP PROCEDURE y luego volver a crearlo con CREATE PROCEDURE. No se puede modificar directamente un procedimiento existente.
Funciones
Las funciones son similares a los procedimientos, pero tienen la particularidad de que devuelven un valor. Se pueden usar en cualquier lugar donde se espere un valor, como en una expresión o en una cláusula SELECT.
Veamos las partes principales con un ejemplo. Supongamos que queremos saber cuántos partidos ha ganado un equipo de fútbol. Para ello, creamos una función que recibe el código del equipo y devuelve el número de partidos ganados.
DELIMITER //
CREATE FUNCTION partidosGanados(equipo VARCHAR(3))
RETURNS INT DETERMINISTIC
BEGIN
DECLARE ganados INT DEFAULT 0;
SELECT COUNT(*) INTO ganados
FROM partits
WHERE (equipc = equip AND golsc> golsf) OR (equipf = equip AND golsf> golsc);
RETURN ganados;
END //
Partes de la función:
- CREATE FUNCTION: sentencia para crear la función, consta del nombre de la función y los parámetros que recibe. En este caso, recibe el código del equipo.
- Parámetros: se declaran entre paréntesis después del nombre de la función, nombre y tipo de dato. En este caso,
equipoes una cadena de caracteres de longitud 3. - RETURNS: indica el tipo de dato que devuelve la función. En este caso, devuelve un entero (
INT). - DETERMINISTIC: indica que la función siempre devolverá el mismo resultado para los mismos parámetros. Esto es importante para optimizar el rendimiento y la caché de resultados.
- BEGIN ... END: delimitan el cuerpo de la función, donde se encuentran las sentencias que se ejecutarán cuando se invoque la función.
- DECLARE: se usa para declarar variables locales dentro de la función. En este caso, declaramos una variable
ganadospara contar cuántos partidos ha ganado el equipo. - SELECT ... INTO: se usa para asignar el resultado de una consulta a una variable. En este caso, contamos los partidos ganados por el equipo y lo asignamos a la variable
ganados. - RETURN: se usa para devolver un valor desde la función. En este caso, devolvemos el número de partidos ganados. Cuando la función ejecuta una instrucción
return, finaliza su ejecución y devuelve el valor especificado al lugar donde se llamó a la función. - END //: indica el final de la función. El
//es un delimitador que hemos definido para indicar el final del bloque de código de la función, ya que dentro de la función también usamos punto y coma para separar sentencias.
Opciones adicionales:
| Opción | Descripción |
|---|---|
| DETERMINISTIC | La función devuelve el mismo resultado para los mismos parámetros |
| NOT DETERMINISTIC | Indica que la función puede devolver resultados diferentes para los mismos parámetros. No se recomienda su uso si no es necesario. |
| READS SQL DATA | Indica que la función realiza operaciones de lectura en la base de datos. |
| MODIFIES SQL DATA | Indica que la función realiza operaciones de escritura en la base de datos. No se recomienda su uso, ya que las funciones no deben modificar el estado de la base de datos. |
Llamada a la función
Para llamar a una función, se debe hacer dentro de una expresión que recoja el valor devuelto. Por ejemplo, si queremos mostrar los partidos ganados por un equipo, podemos hacer:
Esto nos dará en número de partidos ganados por el equipo "bar" (Barça):
SELECT partidosGanados('bar') AS ganados;
SELECT e.codi, e.nom_curt, partidosGanados(e.codi) AS ganados
FROM equips e;
También podemos almacenar el valor devuelto en una variable para usarlo más adelante:
SET @ganadosBarca = partidosGanados('bar');
SELECT @ganadosBarca AS ganadosBarca;
Eliminar una función se hace de forma similar a los procedimientos:
DROP FUNCTION [IF EXISTS] nombreFuncion;
Para nuestro ejemplo sería:
DROP FUNCTION IF EXISTS partidosGanados;
Modificación de funciones
Al igual que con los procedimientos, si queremos modificar una función ya existente, debemos eliminarla primero con DROP FUNCTION y luego volver a crearla con CREATE FUNCTION. No se puede modificar directamente una función existente.
Parámetros y variables
Declaración de parámetros y variables
-
Funciones: En las funciones todos los parámetros son de entrada. Es decir, cuando se llama a la función, se deben pasar los valores de los parámetros.
-
Procedimientos: En la definición de los procedimientos, podemos indicar si los parámetros son de entrada, de salida o de entrada y salida. Pondremos delante de cada parámetro:
-IN: Parámetro de entrada. Es el valor que se le pasa al procedimiento al invocarlo. Es la opción por defecto si no se indica nada.
- OUT: Parámetro de salida. Es un parámetro que se usa para devolver un valor al finalizar el procedimiento. Cuando se llama al procedimiento, se debe pasar una variable (no un valor constante) y el procedimiento asignará un valor a ese parámetro, que podrá ser consultado después de la llamada al procedimiento.
DELIMITER //
CREATE PROCEDURE quantesRutines (IN bd CHAR(64), OUT qFun INT, OUT qPro INT)
BEGIN
select count(*) into qFun
from mysql.proc
where db = bd and type = “FUNCTION”;
select count(*) into qPro
from mysql.proc
where db = bd and type = “PROCEDURE”;
END//
CALL quantesRutines (“lliga1213”, @qf, @qp)//
SELECT @qf as “funcions”, @qp as “procediments//
INOUT: Parámetro de entrada y salida. Es un parámetro que se usa para recibir un valor al invocar el procedimiento y también para devolver un valor al finalizar el procedimiento. Al igual que con los parámetros de salida, se debe pasar una variable al llamar al procedimiento.
DELIMITER //
CREATE PROCEDURE incrementarValor(INOUT valor INT)
BEGIN
SET valor = valor + 1;
END//
SET @x = 5;
CALL incrementarValor(@x)//
SELECT @x; -- Esto mostrará 6
Nombre de los parámetros
Los nombres de los parámetros deben ser únicos dentro del procedimiento o función. No pueden tener el mismo nombre que una variable local o global. MySQL no es case sensitive en los nombres de las variables, por lo que precio, Precio y PRECIO se consideran la misma variable.
Declaración de variables locales
Las variables locales son aquellas que se declaran dentro de un procedimiento o función y solo son visibles dentro de ese bloque. Se declaran con la sentencia DECLARE justo después del BEGIN del procedimiento o función.
El ámbito de visibilidad estará solo entre el BEGIN y END donde se declara la variable.
Sintaxis:
DECLARE nom_var[, ...] tipo [DEFAULT valor];
Siempre se declaran justo a continuación del BEGIN de un procedimiento o función.
En cada sentencia DECLARE se pueden declarar varias variables, pero siempre del mismo tipo y con el mismo valor inicial (DEFAULT). Si necesitamos diferentes tipos de variable o diferentes valores iniciales, debemos usar diferentes sentencias DECLARE.
Ejemplos
DECLARE edad INT; -- Si no ponemos valor por defecto será nulo.
DECLARE precio, importe INT DEFAULT 0;
SET edad = 18; -- Asignamos un valor a la variable;
Variables globales (variables de sesión)
El ámbito de visibilidad es cualquier lugar de la conexión. El valor de las variables globales se guarda mientras está activa la conexión a la base de datos.
Es la única forma de usar variables desde fuera de un procedimiento o función (PA).
no se aconseja usar variables globales en procedimientos o funciones, ya que pueden dar lugar a errores si se usan varias conexiones a la vez.
declaración y ejemplos
Las variables globales no se declaran, simplemente se indican con el signo @ delante del nombre de la variable que queremos usar: @nom_var.
SET @x = 10; -- Asignamos un valor a la variable global @x
SELECT @x; -- Mostramos el valor de la variable global @x
Asignación de valores a las variables
4.4. Assignar valor a les variables
-
Con
SET(ya lo hemos visto antes)SET nom = "Pep"; SET naix = 1970; SET cog = "Garcia", edat = naix + 45; SET @comptador = 0; SET @comptador = @comptador + 1; -
Con
SELECT ... INTO:SELECT nom_alu, cog_alu INTO nom, cog FROM alumnes WHERE codi = 5;
Si la consulta SELECT devuelve más de una fila, dará error. Por lo tanto, es importante asegurarse de que la consulta devuelve solo una fila o usar un LIMIT 1 si es necesario.
- Con
CALL(invocando un procedimiento o función):
CALL nomProcediment(@param1, @param2, ...);
nomProcediment tiene los parámetros de salida, entonces al invocar el procedimiento, el valor de ese parámetro se asignará a la variable global que hemos pasado como parámetro.
Ejercicios de procedimientos y funciones
Ejercicios sin sentencias de control de flujo
Ejercicio 1
Haz la función maxGolejador que le pasas como parámetro un equipo y retorna el dorsal del goleador de ese equipo que más goles ha marcado. A continuación haz las siguientes llamadas para:
- mostrar por pantalla el dorsal que más goles ha marcado del Barça (código "bar").
- mostrar el dorsal que más goles ha marcado de cada equipo.
- mostrar el nombre del goleador que más goles ha marcado de cada equipo.
- incrementar 10000 euros a los jugadores que más goles han marcado en su equipo.
Ejercicio 2
Haz el procedimiento marcar, que le pases como parámetro un jugador (es decir: código de equipo y dorsal) y un partido (es decir: equipo de casa y de fuera) e incremente en 1 los goles de ese goleador y también que incremente en 1 gol el resultado de ese partido. El procedimiento debe retornar el nuevo resultado del partido (goles de casa y goles de fuera). A continuación:
- haz la llamada para decir que ja marcado el dorsal 10 del Barça en el Barça-Valencia (sabiendo que el código del Barça es "bar" y el del Valencia es "val").
- muestra por pantalla el resultado del partido (con los valores retornados antes).
Constructores de control de flujo
Sentencia IF
Sintaxis:
IF condición THEN sentencia
[ ELSEIF condición THEN sentencia ]
[ ELSE sentencia ]
END IF;
Ejemplo
IF a < b AND a < c THEN
SET min = a;
ELSEIF b < c THEN
SET min = b;
ELSE
SET min = c;
END IF;
Sentencia CASE
Sintaxis:
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
Ejemplo con variable
CASE mes
WHEN 1 THEN SET nom = 'gener';
WHEN 2 THEN SET nom = 'febrer';
...
ELSE SET nom = 'error';
END CASE;
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;
Ejemplo sin variable
CASE
WHEN nota >= 0 AND nota < 5 THEN SET text = 'insuficient';
WHEN nota >= 5 AND nota < 6 THEN SET text = 'aprovat';
...
...
END CASE;
Setencia WHILE-DO
Sintaxis:
WHILE condicion DO
sentencias
END WHILE;
Mientras la condición sea verdadera, se ejecutan las sentencias.
ejemplo
CREATE PROCEDURE exemple_while_do()
BEGIN
DECLARE n INT DEFAULT 5;
WHILE n > 0 DO
-- Aquí puedes poner las sentencias que quieras
SET n = n - 1; -- Decrementamos n
END WHILE;
END;
Sentencia REPEAT-UNTIL
Sintaxix:
REPEAT
sentencias
UNTIL condicion
END REPEAT;
Se repiten las sentencias hasta que la condición se cumple. Es como un do-while pero la condición debe ser la contraria para que se ejecuten las sentencias.
ejemplo
CREATE PROCEDURE exemple_repeat_until()
BEGIN
DECLARE n INT DEFAULT 5;
REPEAT
-- Aquí puedes poner las sentencias que quieras
SET n = n - 1; -- Decrementamos n
UNTIL n <= 0 END REPEAT;
END;
Preguntas
¿Hacen lo mismo los dos ejemplos anteriores de do-while y repeat-until?
Operador =
El operador condicional de igualdad se representa por un signo igual (=)
Sentencias LOOP, LEAVE e ITERATE
Sintaxis:
LOOP label
sentencias
[ITERATE label;]
[LEAVE label;]
END LOOP label;
Ejemplo
CREATE PROCEDURE exemple_loop(n INT)
BEGIN
label1: LOOP -- Creación del bucle (loop) etiquetado como 'label1'
SET n = n + 1;
IF n < 10 THEN
ITERATE label1; -- Vamos al inicio del bucle (como el continue de Java)
END IF;
LEAVE label1; -- Salimos del bucle (como el break de Java)
END LOOP label1;
SET @x = n;
END;
LOOP creamos un bucle infinito: no ponemos ninguna condición al principio (como en el while-do) ni al final (como en el repeat-until), sino dentro del cuerpo del bucle: con LEAVE salimos del bucle y con ITERATE volvemos directamente al inicio del bucle. Estas dos sentencias también se pueden poner dentro de los otros bucles que hemos visto.
Sentencias LOOP, LEAVE e ITERATE
Estas sentencias (LOOP, LEAVE e ITERATE) no son recomendables porque rompen la idea de la programación estructurada. Se deben usar con precaución y solo cuando sea necesario, ya que pueden hacer que el código sea más difícil de entender y mantener. En general, es preferible usar las sentencias WHILE-DO o REPEAT-UNTIL para controlar el flujo de ejecución de los bucles.
Ejercicios de procedimientos y funciones con sentencias de control de flujo
Ejercicio 3
Crea el procedimiento insertarGoleador al cual le pasas como parámetro el dorsal, el código del equipo, el nombre del jugador, la cantidad de partidos jugados y la cantidad de goles marcados. El procedimiento debe guardar esa información (en las tablas de jugadores y goleadores) pero debe tener en cuenta primero si ese jugador ya existía o no en la base de datos (ya que deberá hacer inserts o updates en cada caso).
A continución haz tres llamadas al procedimiento:
- Una llamada con un jugador que no existe en la base de datos.
- Una llamada con un jugador que ya existe como jugador pero no como goleador.
- Una llamada con un jugador que ya existe como jugador y como goleador.
A continuació fes 3 crides al procediment per comprovar que funciona correctament:
Ejercicio 4
Crea el procedimiento insertarJornadas a la que se le pasa una cantidad de jornadas y debe insertar tantas jornadas como diga ese número. La fecha no se pondrá y el número de las jornadas será correlativo al último jornada que hay guardada en la tabla de jornadas. A continuación, llama al procedimiento para insertar 10 jornadas. Comprueba que se han creado bien.
Ejercicio 5
Crear una función tipoJugador, que le pasas un jugador (dorsal y equipo) y retorna una palabra dependiendo de los goles marcados. Si 0 goles, “cono”; entre 1 y 10 “normal”; entre 11 y 20 “bueno”; entre 20 y 30 “crack”; y más de 30 “megacrack”. Hazlo con la estructura del CASE. A continuación (usando una llamada a la función):
- Muestra de cada jugador del Barça el nombre y el tipo de jugador que es.
- Muestra los megacracks de la liga: nombre del jugador y nombre
- Muestra cuantos megacracks tiene cada equipo.
Ejercicio 6
Función cantidadJugadores que le pasas como parámetro el código de un equipo y retorna la cantidad de jugadores de ese equipo. Después, mediante llamadas a esa función, haz los siguientes problemas:
- Muestra la cantidad de jugadores del Barça.
- Muestra de cada equipo de más de 25 jugadores: el código, el nombre corto y la cantidad de jugadores que tiene.
- Modifica la tabla de equipos. Hay que incrementar un 10% el presupuesto de los equipos que tienen más de 25 jugadores.
- Modifica la tabla de equipos. Hay que incrementar 1000 euros de presupuesto por cada jugador que tengan.
- Borra los equipos que no tengan jugadores.
Handlers. Gestión de errores
Con SQL podemos gestionar los errores generados por las órdenes SQL. Si, por ejemplo, hacemos un SELECT a una tabla que no existe, nos da el error 1146. Podemos hacer que si alguna vez ocurre ese error, se ejecute una acción específica. Para conseguir esto, debemos definir un HANDLER.
Vemos primero un ejemplo y después explicaremos la sintaxis:
Ejemplo de uso de HANDLER
El siguiente ejemplo debe generar un error de clave duplicada al intentar insertar un registro con una clave primaria que ya existe. Sin embargo, gracias al handler, el error se captura y la ejecución del procedimiento continúa sin detenerse.
El error de clave duplicada es el error 23000 en SQLSTATE, que indica una violación de restricción de integridad, como una clave duplicada. Por tanto indicamoos que cuando ocurra el error 23000, se ejecute una acción específica (en este caso, asignar un valor a la variable @err).
CREATE TABLE prueba (
codi int,
primary key (codi)
);
DELIMITER //
CREATE PROCEDURE demo_handler()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET @err = 1;
SET @x = 1;
INSERT INTO prova VALUES (1); -- Ok
SET @x = 2;
INSERT INTO prova VALUES (1); -- Error (*)
SET @x = 3;
END;
DELIMITER ;
CALL demo_handler();
SELECT @x;
Si ejecutamos este código, veremos que no ha aparecido ningún error y, además, el valor de @x es 3. ¿Por qué?
El error provocado no aparece ya que ha sido "capturado" por el handler que hemos creado. Además, como ese handler estaba definido como CONTINUE, la rutina ha continuado ejecutándose.
Si en vez de CONTINUE, el handler se hubiera definido como EXIT, al ejecutar el segundo INSERT habría finalizado el procedimiento y no se habría ejecutado la sentencia SET @x = 3;. En ese caso, el valor de @x sería 2.
Ahora veamos la sintaxis del handler y las distintas opciones que tenemos para definirlo.
DECLARE tipo_handler HANDLER FOR codigo_error [, ...] sentencia;
Donde tenemos:
- DECLARE: palabra reservada para declarar un handler.
- tipo_handler: nombre del handler, que puede ser cualquier identificador válido. No es obligatorio, pero es recomendable para poder identificarlo más fácilmente.
- HANDLER: palabra reservada que indica que estamos declarando un handler.
- FOR: palabra reservada que indica que estamos definiendo un handler para un error específico.
- codigo_error: código del error que queremos capturar. Puede ser un código de error MySQL, un código SQLSTATE, un nombre de condición o una abreviación como SQLWARNING, NOT FOUND o SQLEXCEPTION.
- sentencia: la sentencia o bloque de sentencias que se ejecutará cuando ocurra el error especificado. Puede ser una sentencia SQL simple o un bloque de sentencias delimitado por
BEGIN ... END.
El código de error
El código de error se puede escribir de distintas formas:
- codigo_error_mysql
- SQLSTATE codigo_error_sqlstate
- nombre_error
- SQLWARNING
- NOT FOUND
- SQLEXCEPTION
Veamos cada una de estas opciones:
-
codigo_error_mysql
Es un código de error numérico.
Ejemplo: 1022 -- Clave duplicada
Problema: estos códigos solo son válidos para MySQL. Por lo tanto, no es portable a otros SGBD.
-
SQLSTATE codigo_error_sqlstate
Es la palabra reservada SQLSTATE más un código alfanumérico, válido para SQL estándar. Ejemplo: SQLSTATE '23000' -- Clave duplicada Un código SQLSTATE equivale a muchos códigos de error de MySQL. Ejemplos:
DESCRIPCIÓN ERROR CODIGO MySQL CODIGO SQLSTATE Clave duplicada en tabla 1022 '23000' Columna no puede ser nula 1048 '23000' Columna ambigua 1052 '23000' Violación de clave ajena 1216 '23000' ... ... ... Tabla desconocida 1051 '42S02' Tabla inexistente 1146 '42S02' ... ... ... Acceso denegado a la BD 1044 '42000' BD desconocida 1049 '42000' ... ... ... ... ... ... Podemos consultar los códigos de error de MySQL y SQLSTATE aquí:
Además, SQLSTATE 'HY000' se puede usar como código de error general.
-
nombre_error
En un nombre de error que hemos declarado previamente como condición. A este error se le conoce como una "condición".
Ejemplo de condición: tabla_desconocida
La forma de declarar una condición es:
DECLARE tabla_desconocida CONDITION FOR 1051; -- o bien: DECLARE error_de_tabla CONDITION FOR SQLSTATE '42S02'; -
SQLWARNING
Es una abreviación para todos los códigos SQLSTATE que comienzan por 01. Se usa para capturar advertencias en lugar de errores.
DECLARE CONTINUE HANDLER FOR SQLWARNING SET @warning = 'Advertencia capturada'; -
NOT FOUND Es una abreviación para todos los SQLSTATE que comienzan por 02. Se usa comúnmente para establecer la condición de recorrer un cursor (lo veremos más adelante).
DECLARE CONTINUE HANDLER FOR NOT FOUND SET @no_encontrado = TRUE; -
SQLEXCEPTION Es una abreviación para todos los códigos SQLSTATE que no son SQLWARNING ni NOT FOUND. Se usa para capturar excepciones generales.
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET @error_general = 'Error capturado';
Ejercicio de Handlers
Ejercicio 7
Queremos hacer un procedimiento que inserte jugadores en la tabla de jugadores, pero queremos gestionar los errores que puedan ocurrir durante la inserción. Para ello:
- Crea una tabla para guardar los errores:
CREATE TABLE errors (
dia DATE,
hora TIME,
taula CHAR(20),
error CHAR(40)
);
- El procedimiento debe recibir como parámetros los valores necesarios para insertar un jugador: código de equipo, dorsal, nombre, lugar y sueldo.
- Crea un handler para que cuando ocurra el error de clave duplicada (código 1062), se inserte el error "Jugador ya existe" en la tabla de errores.
- Crea un handler para que cuando ocurra el error de clave ajena (código 1452), se inserte el error "Equipo inexistente" en la tabla de errores.
- Realiza el `INSERT` en la tabla de jugadores con los valores pasados como parámetros al procedimiento.
-
Crear un procediment que faça les insercions en la taula de jugadors i, si cal, també en la taula d’errors.
- Passa-li com a paràmetres els valors que necessites per a inserir un jugador: codi d’equip, dorsal, nom, lloc i sou.
- Crea un handler per a que quan done l’error de clau duplicada, 1062, (degut a que ja existia el jugador) inserisca l’error “Jugador ja existeix”.
- Crea un handler per a que quan done l’error de clau aliena, 1452, (degut a que l’equip del jugador no existeix) inserisca l’error “Equip inexistent”.
- Fes l’insert en la taula de jugadors amb els valors passats com a paràmetre al procediment.
Haz pruebas, inserta mediante llamadas al este procedimiento diversos jugadores correctos (que no existan pero sí que exista el equipo), que no exista el equipo o que ya exista el jugador. Después mira el contenido de la tabla de errores para comprobar si todo ha funcionado como se esperaba.
Cursores
Los cursores son una herramienta que nos permite recorrer los resultados de una consulta SQL fila a fila. Son útiles cuando necesitamos procesar cada fila de un conjunto de resultados de forma individual, como por ejemplo para realizar cálculos o actualizaciones basadas en los valores de cada fila.
-
Declarar un cursor con un nombre y una consulta asociada:
declaración de un cursor con nombre y una consulta asociada
DECLARE c_alumnes CURSOR FOR SELECT camp1, camp2, camp3 FROM alumnes WHERE curs = “1DAM”;explicación
Hay que respectar el orden de las declaraciones:
- Declaración de variables y condiciones
- Declaración de cursors
- Declaración de handlers
La consulta
SELECTno puede contener la instrucciónINTO. -
Declarar un handler para saber cuándo se sale del cursor:
declaración de un handler para saber cuándo se sale del cursor
DECLARE CONTINUE HANDLER FOR NOT FOUND SET @terminado = TRUE;explicación
Este handler se usa para saber cuándo hemos llegado al final del cursor. Cuando no hay más filas para leer, se activa el handler y se establece la variable
@terminadoaTRUE, lo que nos permite salir del bucle de recorrido del cursor.
-
Recorrer los elementos del cursor:
- Abrir el cursor:
abrir el cursor
OPEN c_alumnes;explicación
Antes de recorrer el cursor, debemos abrirlo con la sentencia
OPEN. Esto ejecuta la consulta asociada al cursor y prepara el cursor para leer los resultados.- Bucle donde, en cada iteración, obtendremos los valores de los campos de la consulta en cada registro:
bucle para recorrer los registros del cursor
-- INICIO BUCLE FETCH c_alumnes INTO var1, var2, var3; -- Aquí haríamos operaciones con esas variables -- FIN BUCLEexplicación
Si el cursor puede devolver más de una fila, debemos recorrerlo con un bucle
WHILE,REPEAT, etc., donde la condición de finalización será la que active el handler cuando ya no queden filas por leer en el cursor.Con
FETCHobtenemos los valores de los campos de la consulta y los asignamos a las variables locales que hemos declarado previamente. Si no hay más filas para leer, se activa el handler y se sale del bucle.- Cerrar el cursor:
cerrar el cursor
CLOSE c_alumnes;explicación
Cerrando el cursor liberamos los recursos asociados a él. Es importante cerrar el cursor una vez hemos terminado de usarlo para evitar fugas de memoria y otros problemas.
Restricciones de los cursores
- Los cursores no pueden ser usados dentro de funciones, solo en procedimientos.
- No se pueden usar cursores dentro de otros cursores.
- No se pueden usar cursores dentro de sentencias
IF,WHILE,REPEAT, etc. - No se pueden usar cursores dentro de transacciones (es decir, no se pueden usar dentro de bloques
BEGIN ... COMMIT). - Los cursores no pueden ser usados en consultas que modifiquen la tabla (como
INSERT,UPDATEoDELETE).
Los cursores de MySQL son solo de lectura (no podemos modificar los valores de la tabla ni borrarlos) y solo se mueven hacia adelante (hacia el siguiente registro siguiendo el ORDER BY de la consulta del cursor).
Ejemplo de cursor
Vamos a ver un ejemplo para ver como funcionan los cursores.
Enunciado
Vamos a crear un procedimiento que guarde en una tabla el resultado de la quiniela de una jornada. Para ello, primero crearemos la tabla quinieles y luego el procedimiento fer_quiniela, que recorrerá los partidos de una jornada y guardará el resultado en la tabla quinieles. EL procedimiento aceptará como parámetro el número de jornada y recorrerá los partidos de esa jornada para calcular el resultado (1, X o 2) y guardarlo en la tabla quinieles.
Estuctura de la tabla quinielas:
CREATE taBLE quinielas (
equipc CHAR(3),
equipf CHAR(3),
jornada INT,
resultat CHAR(1)
);
hacer_quiniela que recorrerá los partidos de una jornada y guardará el resultado en la tabla quinielas.
DELIMITER //
CREATE PROCEDURE hacer_quiniela(j INT)
BEGIN
-- 1. Declaración de variables
DECLARE ec, ef CHAR(3);
DECLARE gc, gf INT DEFAULT 0;
DECLARE resul CHAR(1);
DECLARE fin_cursor INT DEFAULT 0;
-- 2. Declaración del cursor
DECLARE c_partidos CURSOR FOR
SELECT equipc, equipf, golsc, golsf
FROM partits
WHERE jornada = j;
-- 3. Declaración del handler para salir del cursor
DECLARE CONTINUE HANDLER FOR NOT FOUND SET fin_cursor = 1;
-- 4. Recorrido del cursor
OPEN c_partidos; -- Abrimos el cursor
REPEAT
FETCH c_partidos INTO ec, ef, gc, gf; -- Recuperamos datos
IF NOT fin_cursor THEN -- Comprobamos que no se ha llegado al final
CASE
WHEN gc > gf THEN SET resul = '1';
WHEN gc = gf THEN SET resul = 'x';
ELSE SET resul = '2';
END CASE;
INSERT INTO quinieles (equipc, equipf, jornada, resultat)
VALUES (ec, ef, j, resul);
END IF;
UNTIL fin_cursor END REPEAT;
CLOSE c_partidos; -- Cerramos el cursor
END //
Ejercicios de cursores (BD futbol)
Ejercicio 8
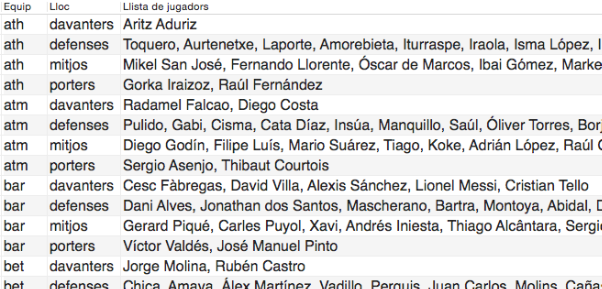
Crea la función llistaJugadors, a la cual le pasas un código de equipo y un lugar de jugador ("porter", "defensa", ...) y retorna una cadena de caracteres con los nombres de los jugadores de ese equipo en esa posición, separados por comas. Recuerda que puedes usar la función concat.

Ejercicio 9
Usando la función anterior, muestra de cada equipo los jugadores que juegan en cada posición (davanters, defenses, mitjos y porters), de forma que salga así:
Disparadores (Triggers)
Introducción
Un disparador és un bloc de codi que s’executa automàticament quan es realitza una acció específica sobre una taula, com ara una inserció, actualització o eliminació de dades. Els disparadors són útils per a mantenir la integritat de les dades, auditar canvis o automatitzar tasques relacionades amb les dades.
por ejemplo dada la siguiente tabla:
CREATE TABLE cuentas(
id INT PRIMARY KEY,
saldo DECIMAL(10, 2)
);
CREATE TRIGGER antes_ins_cuenta
BEFORE INSERT ON cuentas
FOR EACH ROW SET @suma = @suma + NEW.saldo;
antes_ins_cuenta, que se ejecutará antes de insertar una fila en la tabla cuentas. La acción que realiza es acumular el saldo de la nueva cuenta en la variable @suma.
Como que @suma es un acumulador, antes de usarlo debemos inicializarlo a 0:
SET @suma = 0;
INSERT INTO cuentas VALUES (1, 100), (2, 150), (3, 200);
INSERT INTO cuentas VALUES (4, 250);
SELECT @suma; -- Mostrará la suma total: 700
Sintaxis de los disparadores
CREATE TRIGGER [nom_bd.]nombre_disparador
{BEFORE | AFTER} {INSERT | UPDATE | DELETE} ON nombre_tabla
FOR EACH ROW sentencia
La sentencia puede ser una sentencia SQL simple o un bloc de sentències delimitat per BEGIN ... END. En la sentencia puede haber sentencias condicionales, bucles, etc.
ciclo de vida de un disparador
Cuando se hace una acción sobre una tabla, primero se ejecuta el bloque asociado al BEFORE, luego la propia acción (insert, update, delete) y después el bloque asociado al AFTER. Por lo tanto, si alguna de estas acciones da error, no se ejecutarán las siguientes.
Para eliminar un disparador, se usa la sentencia DROP TRIGGER:
DROP TRIGGER [nom_bd.] nombre_disparador;
Los alias OLD y NEW
En la sentencia que se ejecutará para cada registro afectado, se pueden hacer referencia a los valores de este registro antes y/o después de hacer una acción de update/insert/delete:
-
Si se hace un UPDATE:
- OLD.nombre_campo es el valor del campo antes de ser modificado
- NEW.nombre_campo es el valor del campo después de ser modificado
-
Si se hace un INSERT:
- (OLD.nombre_campo no tiene sentido)
- NEW.nombre_campo es el valor que se inserta en ese campo
-
Si se hace un DELETE:
- OLD.nombre_campo es el valor del campo del registro que se borra
- (NEW.nombre_campo no tiene sentido)
Limitaciones de los disparadores
-
Limitaciones en los nombres
- Un disparador no puede tener el mismo nombre que otro disparador de la misma tabla. Es recomendable que en una misma base de datos no se repitan los nombres de los disparadores.
-
Limitaciones en los tipos
- En una tabla no pueden haber dos disparadores del mismo tipo. Por ejemplo, no puede haber dos disparadores
BEFORE UPDATE.
- En una tabla no pueden haber dos disparadores del mismo tipo. Por ejemplo, no puede haber dos disparadores
-
Limitaciones en la sentencia
- No se puede usar la sentencia
CALL(invocar procedimientos almacenados), pero sí se pueden invocar funciones. - No se pueden iniciar o finalizar transacciones (
START TRANSACTION,COMMIToROLLBACK). - En un disparador
BEFORE INSERT, el valor deNEWpara una columnaAUTO_INCREMENTes 0. -
Permisos:
- Para hacer
SET NEW.nombre_campo = valor, se necesita permiso deUPDATEsobre la columnanombre_campo(y hacerlo en disparadores de tipoBEFORE). - Para hacer
SET nom_var = NEW.nombre_campo, se necesita permiso deSELECTsobre la columnanombre_campo.
- Para hacer
- No se puede usar la sentencia
Algunas utilidades de los disparadores
-
Actualizar campos de tablas que dependen del valor de otros campos: por ejemplo, al importar una línea de factura, actualizar el total de una factura...
-
Modificar los valores a introducir en la tabla (con
BEFORE INSERToBEFORE UPDATE):
Ejemplo de disparador para controlar notas
Supongamos que tenemos una tabla notes con un campo nota que debe estar entre 0 y 10. Podemos crear un disparador que se ejecute antes de actualizar el campo nota y que lo ajuste si es necesario:
delimiter //
CREATE TRIGGER nota_ok BEFORE UPDATE ON notes
FOR EACH ROW
BEGIN
IF NEW.nota < 0 THEN
SET NEW.nota = 0;
ELSEIF NEW.nota > 10 THEN
SET NEW.nota = 10;
END IF;
END; //
delimiter ;
Ejercicios de disparadores
Ejercicio 10
En la base de datos de fútbol, queremos asegurarnos de que el campo gols de la tabla golejadors siempre sea la suma de los campos gtitular y gsuplent. Para ello:
a) Crea los disparadores necesarios para asegurar que el campo gols siempre será la suma de los otros dos.
b) Inserta algunos registros en la tabla golejadors y modifica algunos registros, poniendo valores que no sumen correctamente los goles como titular y suplente. Después comprueba que ha funcionado: mira si los goles son igual a la suma de los otros dos campos.
Ejercicio 11
Queremos tener en la tabla de equipos un campo que guarde la cantidad de defensas que tiene cada equipo (aunque sabemos que será un campo redundante, ya que se podría calcular a partir de la tabla de jugadores). Para ello, haz lo siguiente:
a) Añade a la tabla de equipos el campo qdefenses.
b) Rellena los valores de esa columna para cada equipo existente en la base de datos.
c) Crea los disparadores necesarios para mantener siempre actualizado ese campo.
d) Haz cambios con los defensas de la base de datos para ver que los disparadores funcionan.
Permisos de los procedimientos y funciones
Los permisos de los procedimientos y funciones se gestionan de forma similar a las tablas y vistas. Los permisos se pueden otorgar a los usuarios para que puedan crear, modificar o ejecutar procedimientos y funciones.
Dar permisos para crear un PA
GRANT CREATE ROUTINE ON nom_bd.* TO nom_usuari;
A partir de ese momento, el usuario nom_usuari podrá crear procedimientos y funciones en la base de datos nom_bd. Tendrá permisos de ejecución, modificación y eliminación sobre los procedimientos y funciones que cree.
Dar permisos para modificar un PA
GRANT ALTER ROUTINE ON PROCEDURE nom_proc TO nom_usuari;
A partir de ese momento, el usuario nom_usuari podrá modificar el procedimiento nom_proc.
Dar permisos para ejecutar un PA
sql
GRANT EXECUTE ON { PROCEDURE | FUNCTION } nom_proc TO nom_usuari;
A partir de ese momento, el usuario nom_usuari podrá ejecutar el procedimiento nom_proc.
Quitar permisos de un PA
REVOKE { CREATE ROUTINE | ALTER ROUTINE | EXECUTE }
ON nom_proc
FROM nom_usuari;
Ejemplos:
REVOKE CREATE ROUTINE ON * FROM nom_usuari;
REVOKE ALTER ROUTINE ON PROCEDURE nom_proc FROM nom_usuari;
REVOKE ALTER ROUTINE ON FUNCTION nom_func FROM nom_usuari;
REVOKE EXECUTE ON nom_proc FROM nom_usuari;
Tablas del sistema asociadas a los procedimientos y funciones
- La tabla mysql.proc contiene información sobre los procedimientos y funciones creados (nombre, propietario, etc.).
- La tabla mysql.procs_priv contiene información sobre los permisos de los procedimientos de cada usuario.